

What is annotation and why 4D LiDAR semantic segmentation will drastically improve Autonomous Driving development



Before they’re rolled out to the public, self-driving cars, robots and autonomous systems must be able to reach a detailed level of perception and understanding of the physical world around them. How do we get them to that point? Today, we do so by relying on computer vision, Machine Learning and multiple sensors. Usually, these sensors include cameras, radars, sonars and LiDARs, or Light Detection and Ranging.
Each AV (autonomous vehicle) company has its own approach in deciding which sensor suite to adopt, how to place the sensors and how to make use of the fused collected data. LiDAR, a piece of hardware which has undergone a rapid evolution over the past few years, has become increasingly more important due to its fundamental role in helping autonomous vehicles safely navigate our roads. Despite Elon Musk's claims to the contrary, the AV industry at large is convinced about the key relevance of this sensor and its capabilities for the success of autonomy. Contrary to cameras, in fact, LiDAR sensors can still perform well in adverse visibility conditions such as bad weather or even shadows and ambiguous light situations when cameras struggle.
Once an autonomous car hits the road, it collects huge amounts of data through all of these sensors. But what’s the destiny of that data, and what is it used for? One of the most important uses of that data is to train machine learning models so that autonomous cars, or any other autonomous system, can learn how to navigate the world. What does this actually mean? And how can the model learn from this data? Well, the answer is “data annotation and labeling” and it involves an astonishing amount of manual work. In fact, it can take up to 800 man hours to annotate just one hour of driving.
On a practical level, it means that every image of every frame needs to be vetted by humans using their brain — which, let’s face it, is still way smarter than any autonomous system when it comes to understanding their environments — who then label and annotate every object in the scene, or at least double check the labels automatically generated by algorithms. Everything in each frame needs to have a name attached to it. Just like a child in elementary school who colors drawings according to specific categories, we also teach computers to recognize and categorize objects in the same way.
Getting Started: Understanding Image Annotations
We are all bombarded by images every day, so it’s pretty easy to understand how image labeling datasets is done. Although there are different ways to represent and identify objects in a way that is understood by machines, one of the most common is to draw bounding boxes around objects, like in the image below:

As you can see, every object in the picture is labeled according to two main classes: “Pedestrian” or “Car”. In this case, the distinction is quite high-level and not very detailed, but, as you can imagine, the annotation task can be fine-tuned to include more detailed classes or enrich particular classes with specific attributes. For example, instead of labeling someone as just a “pedestrian,” they could be labeled as a woman or a man. And objects — let’s say a car — could be labeled as “Lights on” or “Lights off.”
But our world is not flat, and image labeling could go even further by trying to capture some sort of 3-dimensionality through cuboids instead of bounding boxes, like in the image below.

The types of labels (bounding boxes, cuboids etc.) and level of refinement chosen are dictated primarily by the goal of the engineers using it and the type of usage they want to make with the annotated dataset.
As mentioned, cameras are not the only sensors used in vision-based autonomous systems. So, what do LiDAR datasets look like? Simply put, they’re a cloud of points. LiDAR works by emitting laser beams all around and measuring the time-of-flight of the signal bumping from an object back to the receiver. In this way, LiDAR can build a 3D representation of the world drawing a point in the space every time one of its lasers hit something. Or, to be more precise, that’s currently our best way of visualizing data collected by LiDAR, and it looks more or less like the image below:
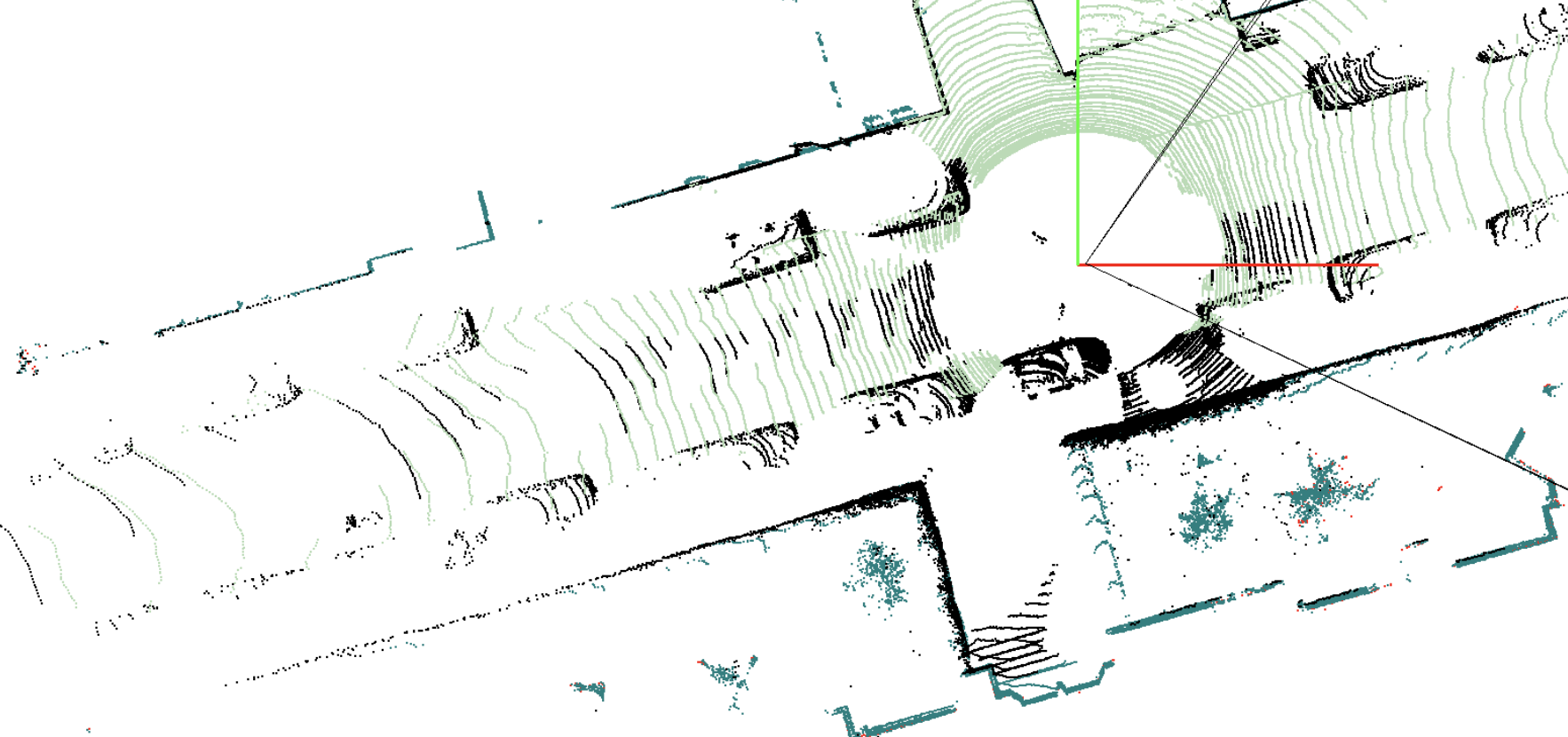
Example of LiDAR frame visualization. Source KITTI dataset.
LiDAR annotation and labeling is very similar to image labeling in its essence, but different in practice for a simple reason: It is a 3D representation on a flat screen. In addition, humans have to deal with a huge amount of points (in the order of millions) which are not contained by specific surfaces or boundaries. So, even for the human brain, it is not so trivial to understand which point belongs to which object, and if you zoom into the point cloud image, this difficulty becomes clear. Even for LiDAR data, annotation is mostly done using the same ideas that guide the image labeling practices, such as bounding boxes or cuboids. See an example below:
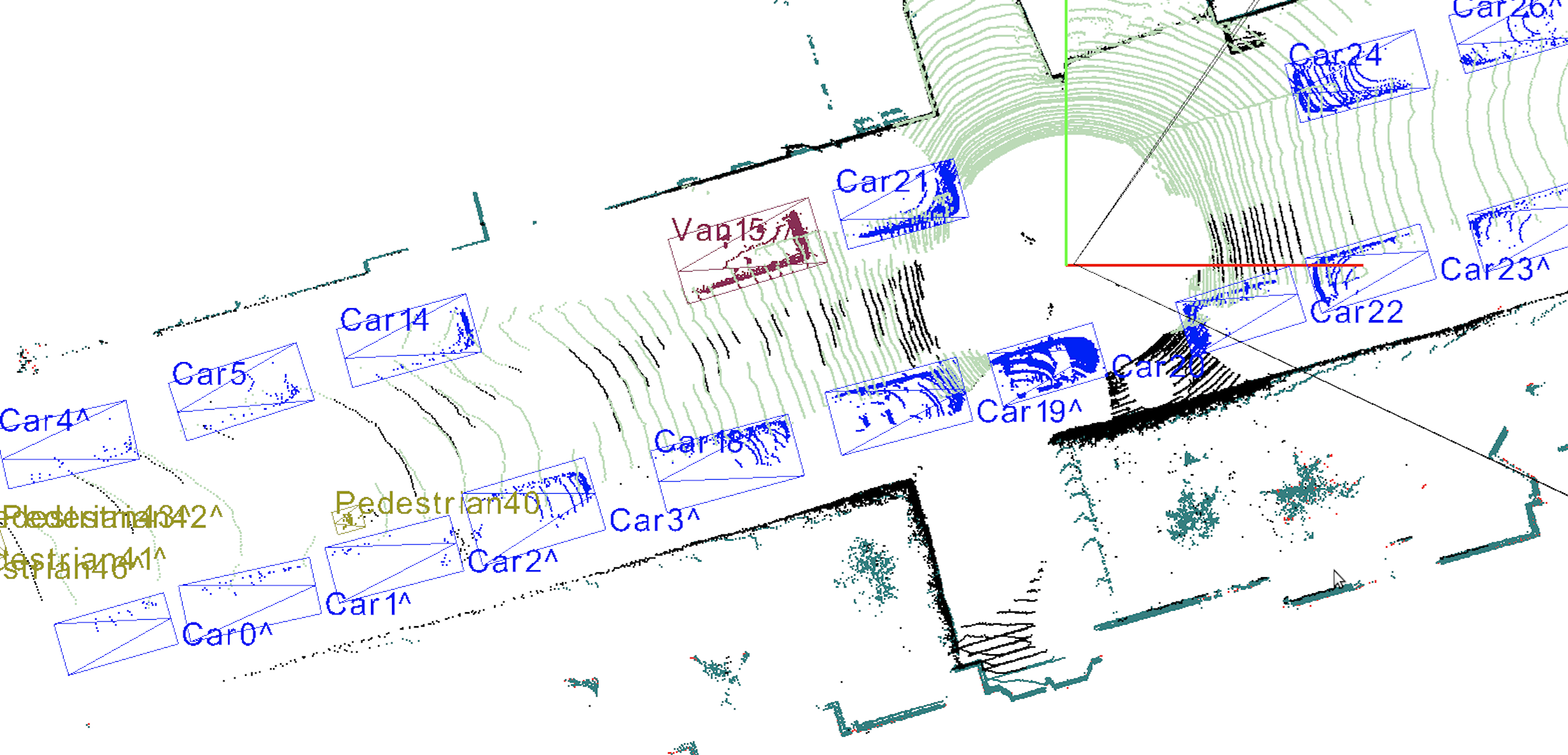
Bounding boxes on LiDAR frame. Source KITTI dataset.
Are boxes the best we can do?
At this stage, one thing should be evident: We are pretty good at recognizing what is around us, and we do not use bounding boxes or cuboids to do so. Teaching machines to recognize and interpret the environment through box image labeling is very practical and relatively easy, but it is not the most detailed and insightful way of doing it.
A deeper level of description and understanding could be achieved through what is known as semantic segmentation. When drawing a box around an object in an image, for example, there usually are a significant amount of pixels that fall into that box but don’t actually belong to that specific object. Semantic segmentation overcomes that pitfall by labeling each individual pixel on an image. The result (pictured below) is that every pixel is colored according to the class it belongs to. Pedestrians are red, trees are green and cars are blue. These labels are attributed at the pixel level, rather than the more general and imprecise box level. This results in a much more detailed interpretation of the world.

If we want to dive one level deeper, we arrive at Instance Segmentation, which basically means that we not only discern among objects belonging to certain classes, but we want to teach the machine to recognize every single object as a particular “instance” of a more general class. It is great to be able to identify humans, but it’s even better to be able to identify each person within the human class, since we are not completely equal to each other. Instance segmentation looks like the image below:

Semantic segmentation and semantic scene understanding are crucial for a wide range of applications for self-driving cars. If so, there should be an equivalent for LiDAR datasets too, and there is — but it comes with some tough challenges.
While image data are encoded in pixels, we saw that LiDAR data is represented by points spread throughout their 3D environment. So, to semantically segment LiDAR points means that every single point needs to be attributed to a specific class of objects, and there are millions of points to be colored in a meaningful way. See a semantically segmented frame below:
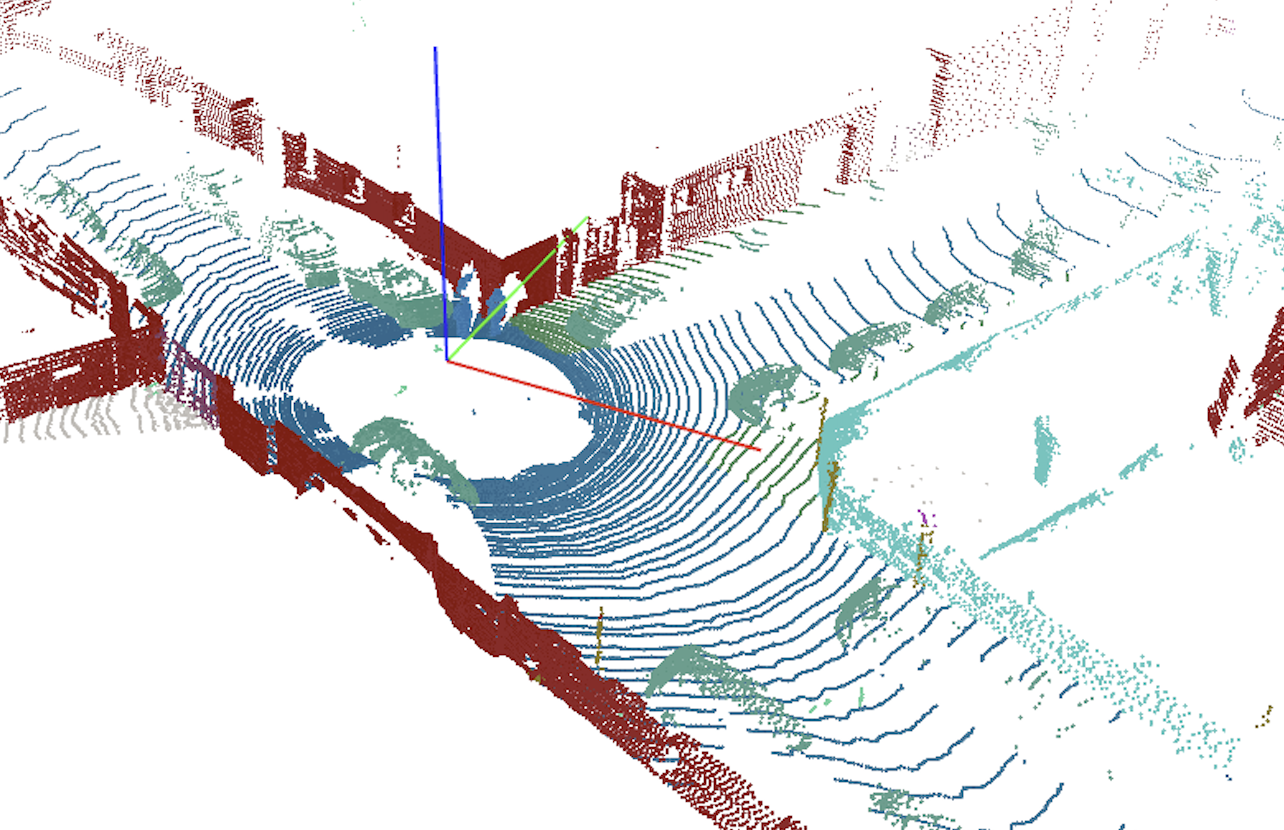
Point level semantic segmentation. Source KITTI labeled dataset.
The task of manually segmenting every single point in the scene is massive and requires a lot of attention to detail in order for the machine to be able to gain a solid understanding of the world.
Deepen.ai’s 3D tool is designed and optimized specifically to optimize this labeling process, both with respect to accuracy and velocity. However, as you can imagine, it is still a demanding job for humans.
The biggest challenge in this context is represented by sequences of frames. Autonomous vehicles drive around miles of roads producing LiDAR sequences of data over time. So, every point in each frame needs to be labeled, turning what it already a demanding job into a massive task for humans. Why is the problem of sequences so important and how is it “partially” solved today?
Solving The Sequence Problem
Going back to images and bounding boxes, the sequence problem is somehow solvable. One of the current approaches taken is to let the human labelers annotate only some ‘key’ frames in the sequence and have the intelligent algorithms of the software figure out where to place the labels (boxes) in the frames (images) in between the key frames through mathematical processes based on interpolation. In this situation, the choice of the key frames can play an important role, and depending on which key frames are manually labeled, the software is able to produce better or worse results.
If we think about semantic segmentation of 3D LiDAR sequences, the problem is not easily solvable anymore, meaning that as of today it is still a challenge to semantically segment long sequences of ground truth LiDAR data in a way that is fast, accurate and efficient — not only in terms of human labor but also in terms of computation efficiency.
This is a huge problem for the whole autonomous vehicle industry. On one hand, semantically segmented LiDAR data can bring a ton of advantages and unlock a wide array of innovations and advances in the field. On the other hand, it is too cumbersome, time-consuming, resource-demanding and expensive to have LiDAR semantic segmentation available at large. It is arguable that the unavailability and inaccessibility of LiDAR dataset with semantic segmentation is holding back AV companies to reach important milestones in their quest to autonomy.
Deepen’s 4D LiDAR annotation technology is solving the issue by making semantic and instance segmentation of long sequences of LiDAR data highly efficient and accurate. Now it is possible to segment those long sequences in minimal time and with exceptional results, compared to what was available yesterday.
Deepen 4D LiDAR technology in action:

Point level semantic segmentation of LiDAR sequence. Source KITTI labeled dataset.
The Advantages of 4D Semantic Segmentation of Long Sequences of LiDAR data
Look outside your window. Maybe you’re facing a road, a park, or another building. No matter what you’re seeing, but it is clear that not everything of the world outside of your window can be fitted meaningfully into a box. Think about atmospheric agents for example, or sparse fluids and gases. In addition, there are many cases in which boxes overlap with each other: a person on a chair, or a car parked right under the foliage of a big tree, for example. In all of these cases, boxes cannot be very precise in specifying which is what — it’s just a loose form of annotation and labeling.
That’s why semantic segmentation is so important, and it becomes even more crucial for LiDAR labeling tools, which are a fundamental part of the perception stack of self-driving cars. Labeling LiDAR data with bounding boxes is definitely not the most accurate picture of the world in which self-driving cars have to safely navigate. Semantic segmented data, instead, provide machine learning models on which AV rely, with a deeper and finer interpretation of their surroundings.
Moreover, how can we make sure that the autonomous systems we develop (aka self-driving cars) are safe enough to circulate on our roads without human intervention? Benchmarking is a crucial part of that. Benchmarking in the process of comparing the results of the software in understanding the scenario with the actual real world out there (ground truth). As of today, HD maps are being built with millimeter accuracy: every single tree, stop sign, sidewalk, needs to be located with extreme accuracy within the constructed map. As HD maps representing the real world are immensely accurate, so our algorithms should be. Training Machine Learning models on point level semantically segmented ground truth data is arguably the best way we have as of today to meet that level of precision.
These are just one of the many concrete applications that 4D semantic segmentation capabilities can unlock. Undoubtedly though, the ability to easily segment 3D point cloud sequences at scale will have a significant impact on many autonomous systems such as agricultural robotics, aerial drones, and even immersive 3D real-world AR and VR experiences.
So, enjoy the ride and fasten your seatbelts... This might be one of the last times you’ll have to do it.
